
In 1990, Tim Berners-Lee invented a distributed hyperlinked information management system he called the World Wide Web, known today simply as “the Web”. It was meant as a way for humans to publish content intended to be read by other humans, and its simplicity, efficiency, and versatility led to quick and sustained success. The Web quickly became the de facto standard for content publishing on the Internet, the emerging global network layer at that time. The combination of both overtook all other systems and this initial web – a vast collection of static sites of read-only pages of content known as Web 1.0 – became the foundation on which modern computing developed, transforming the world more than anyone could have imagined.

Figure 1: A timeline of the World Wide Web, from 1.0 to 3.0
Twelve years later, Web 1.0 underwent a major transformation: Due to the evolution of underlying technologies and to widen its use and adoption, it became less one-way. The Web evolved into an interactive platform where each user could be an active contributor instead of just a passive reader. It saw the emergence of forums, personal websites, blogs, and wikis, which ultimately led to the development of social networks such as LinkedIn (2003) and Facebook (2004). This shift would be understood as the rise of the Social Web, or Web 2.0.
Another decade later, and on the back of a seminal 2001 article by Berners-Lee, the Web evolved again: This time, the ecosystem would not be limited to human content creators and consumers but opened as a platform to and for machines. On this platform, computers could find and use information needed to solve complex questions and execute tasks that required dynamically aggregating information from multiple sources. Whether organizing a vacation or diagnosing a rare disease, computers could leverage the richness and decentralized nature of Web 1.0 that made it so successful. This new Web would become known as Web 3.0, the Web of Data, or the Semantic Web, and it would give rise to new technologies necessary for letting computers unambiguously exchange information, such as RDF. Web 3.0 still needs to mature but new enablers such as machine learning and the IoT will continue to drive its development.
Technical documentation has the same objective as Web 1.0, and it delivers it in much the same way that the Web was delivered twenty years ago: static publishing of one-way textual content by humans to be read by other humans. Yet, considering the evolution of the web from static to social and to semantic, what evolution can we expect for technical documentation? How could Tech Doc be reshaped from passive one-way content into something “social”, and then something “semantic”? What will Tech Doc 2.0 and Tech Doc 3.0 look like? How will they change the way users interact and participate with tech docs? What does Semantic Tech Doc mean and what could it enable? If we want to be ready for and foster this transformation, these are questions that demand examination.
Social Tech Doc
To imagine what Tech Doc 2.0 could be, we can consider two different use cases and user engagement situations: one-to-few and one-to-many.
One-to-Few
The one-to-few scenario exists when a user wants to contextualize the tech doc, adapt it to their needs, capitalize on their knowledge, and share it internally with a limited group of users. A typical one-to-few use case is the maintenance of a machine, where a technician wants to take notes on the documentation to keep track of something done during service or to transmit important information for a future operation. In the past, the technician might have done this with a pen in the margin of a spiral-bound manual but, with static Tech Doc 1.0, this is difficult if not impossible.
When publishing static and read-only content in the Web 1.0 style, we force users to copy-paste content so that they can adapt it and create documents of their own on the side. If we want to support users in engaging with existing content, Tech Doc must evolve from being “just” content to being the basis for a full-featured platform. The textual content is only a fraction of the value proposition here as the tools allowing users to read, comment, highlight, and share become an integral part of the solution in much the same way that a social network like Facebook or Instagram is as much an application as it is a repository of content.
Hence, Tech Doc 2.0 is not just a set of PDFs or some HTML on a website. Instead, we must think of it as a rich application that not only gives access to content through search and read capabilities but also embeds features dedicated to content interaction and group sharing.
One-to-many
The one-to-many scenario is even more challenging: It entails a radical change in the way content is produced, and perhaps even in the definition of technical documentation itself.
In the classical paradigm of tech doc creation, tech writers interview people, try to understand every part of the product, draft manuals, and then have them reviewed by experts to ensure their accuracy. More advanced companies have revised this process to increase their writing throughput: Tech writers design the storytelling, have SMEs write the details, and then review, proofread, and align content to ensure its consistency. This latter approach broadens the base of stakeholders involved in knowledge production, but it still maintains tight control over the process by engaging only a limited number of people under the direction of internal stakeholders.
At the core of Web 2.0, though, is the notion that anyone can be a contributor. For tech doc, this means empowering people external to the company such as partners, resellers, customers, and end-users to be content producers, allowing them to provide not just comments and feedback but also to create real content. These external sources have developed expertise about the product and often have done things your internal teams could not have imagined, solving problems in creative ways, and pushing the boundaries as they develop new use cases. And all of this is exactly what other users would like to learn.
Many companies address this demand by providing a forum or a community website distinct from the documentation portal, where users can ask for tips from other users, offer help, and share what they do and how they do it. For companies that haven’t set up such sites, it is still common to see posts and threads spawning on external social platforms entirely out of the sight and control of the company. Yet, this “forum approach” is far from adequate: Discussions are volatile and lack clear contextual information, making it difficult to be sure whether a solution might be applied in a similar situation. As a result, forums often see the same question asked multiple times demonstrating a low level of confidence by users in past threads. Additionally, these forums are a place where people go to solve problems by asking others rather than a tool where knowledgeable users are encouraged to proactively share expertise. Blogs or wikis would both be tools that are better adapted to such sharing, yet either would be just another site for a company to set up and yet another silo where information might be lost. In short, usually all a company gains by deploying such community sites is transient information lacking context despite the certain value that might be derived from these contributions and the volunteers who provide them.
Now imagine a documentation platform that would allow users to start discussion threads grounded in the documentation and hence within a specific and unambiguous context. These discussions and tips would be an added layer of information to the core documentation, multiplying its value by adding details on how it applies to real use cases. These threads would not be limited to simple short phrases like a comment in a Microsoft Word document but instead could be rich text containing examples, code samples, screenshots, video, and more. In effect, these contributions would resemble fully featured documentation, which naturally leads to an obvious question: What if users could write and publish documentation just like the tech writer team does – not only comments on content that already exists but entirely new standalone documents?
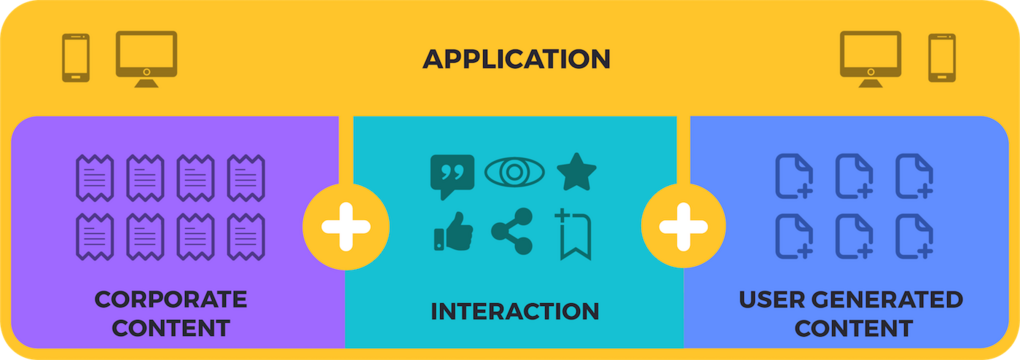
Figure 2: Applications that mix user interactions and content create new user experiences
Impossible? Too dangerous? A good chance that the user-generated content could be inappropriate, misleading, or wrong? Let’s see.
Tech Doc 2.0 – A necessary paradigm shift
This is a change of paradigm that is somewhat frightening, as all paradigm shifts are, yet there is no good reason to reject this evolution in tech doc creation.
First, a social documentation portal is not an open-to-the-world social network like Facebook. It’s more likely to be a B2B portal and the user-generated content capacity can be restricted to authenticated users that are known individuals, working with one of your customers, and listed in your corporate directory. Social network experience has proven that when people are identifiable, they are more likely to behave.
Second, what is published by end users could be clearly tagged as such, or even displayed differently with styling visibly distinct from existing and certified “home-grown” content. User-generated content might also be excluded from default search results so that users seeking it must specifically extend their searches.
Companies could choose to have internal reviewers be charged with validating such content before making it accessible to visitors, with visibility remaining limited to the author, or to the members of his team in the meantime, a temporary one-to-few scenario as discussed above. Alternatively, companies could also leverage the wisdom of their crowd by encouraging readers to rate end user-created documents, and then automatically surface content that has proven to be valuable to others. Or mix both approaches: Review only content that has been tagged as valuable by the crowd so that it is marked as approved and then automatically included with the official content.
Going one step further again to advance the process, users that contribute to highly rated or approved content can be given credit so that any new contribution they make is given a higher score from the outset. Such a strategy leads to a focus on how to motivate users to participate and share socially, and shows how the principles of gamification can be applied to tech doc.
Confidence in this approach can also be gained by considering one of the most successful Web 2.0 experiments, Wikipedia. In just a few short years, Wikipedia overcame all competing encyclopedias (see text box below) and continues to grow in reputation and usability with each passing year.
From a technological standpoint, it is obvious that everything discussed here is only possible if it is natively supported by the content delivery platform, which itself must evolve from a search-and-read website to a truly collaborative solution.
The case of the encyclopedia Before the Web, scholarly knowledge was conveyed to the masses through imposing sets of books that were a must-have in any respectable house – it was the heyday of the leather-bound brands such as the Encyclopedia Universalis and the Encyclopedia Britannica. Encyclopedias shifted to digital formats with the rise of the Web, and new digital competitors were born, such as Microsoft’s Encarta. Yet, the principle behind the digital encyclopedia remained unchanged from its printed predecessor: Knowledge was written by few experts and released in a top-down, one-way manner. With the advent of Web 2.0, however, came a paradigm shift to an industry that had resisted all change for most of the previous two millennia. Within just a few years, the open and collaboratively edited Wikipedia became the world’s go-to source for factual knowledge. A social creation, many scholars and academics criticized the standard of articles and doubted that it could ever replace its historied rivals. After all, how could knowledge produced by anyone with an internet connection ever be trusted? Yet, scientific studies have shown that Wikipedia has, with time, proved just as reliable and far more complete than its historic counterparts. In the same vein, then, why would information written by users and partners be less reliable than knowledge produced by a team of tech writers? For more, see |
Semantic Tech Doc
The Semantic Web is an evolution of the Web, which originates from the idea that its distributed nature is its force. It is scalable in all dimensions: the number of contributors, the depth and richness of content, traffic, users, and more. The Web is fast, resilient, and adaptable. When it comes to content, the Web has outgrown any past enterprise, system, or database that has tried to capture and represent information in a centralized way.
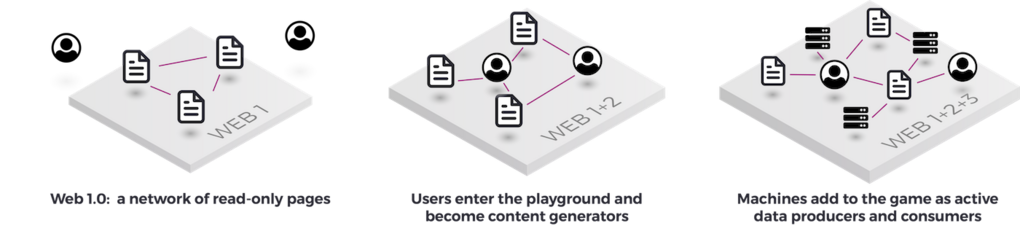
Figure 3: The evolution of the Web – the fundamental transformations brought by Web2.0 and Web 3.0
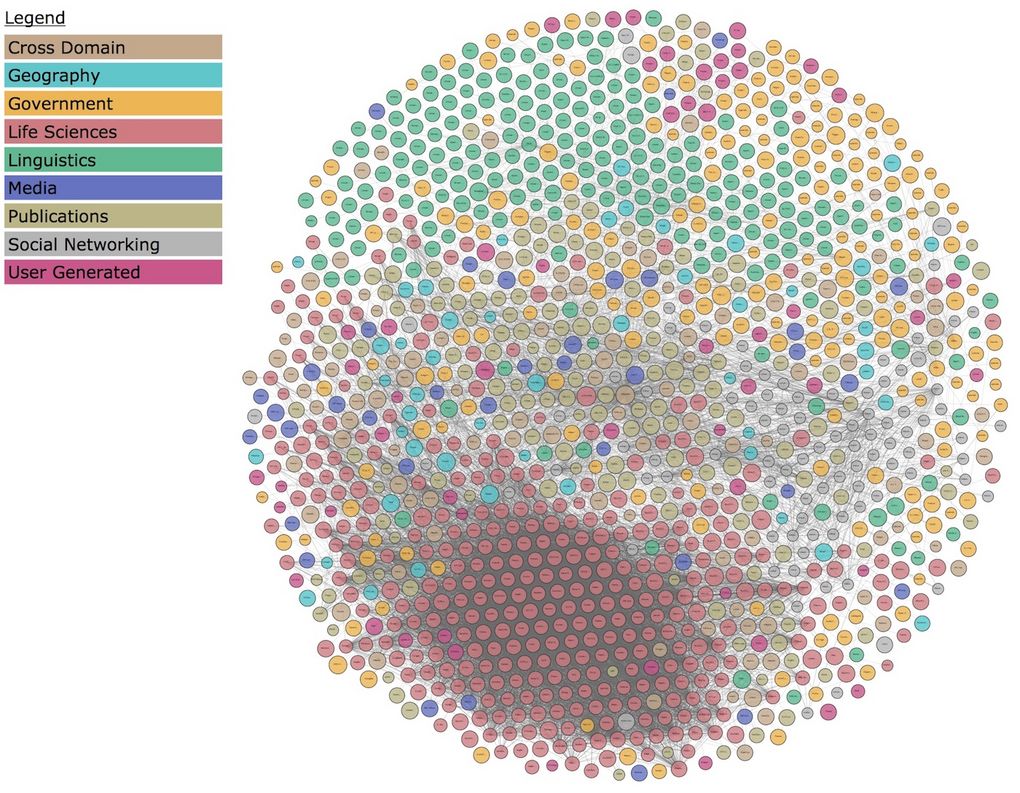
Figure 4: The Linked Open Data Cloud
https://lod-cloud.net/
The challenge then is, how to leverage the existing Web 1.0 that has been designed for humans so that it can be turned into a platform where machines could also be information consumers and publishers. This evolution has led to the definition of new technologies to support the modeling and exchange of information between machines (among them OWL, RDF, and SPARQL) and to the emergence of Linked Open Data, a web of interlinked structured content consisting of thousands of sites exposing databases and actionable information (see lod-cloud.net). The availability and sharing of knowledge at scale via the Web have been instrumental in the rapid progress of biology and medicine, including genome sequencing, in recent years. Scientists today use the Semantic Web as their preferred medium for publishing and exchanging data.
How can this evolution of the web inspire a similar shift in technical documentation?
Use case: The production line
Consider the case of a production line in an ACME Corp fab made up of dozens of different machines for cutting, folding, soldering, and painting, originating from several different vendors, with each machine itself a collection of subsystems from different providers.
How can ACME technicians efficiently maintain or repair such a production system?
ACME would need to collect and store a copy of the documentation for each machine, and possibly for some of the different machine components as well. They would end up with a vast collection of unrelated and unorganized PDF files on a file server somewhere, something that field technicians will struggle to find when they need it. Even if the documentation from each vendor is available online, the technician would need to navigate each vendor’s portal and find the right documentation to execute a single maintenance task.
Now imagine instead that each vendor makes the documentation for its machines accessible in a fine-grained and normalized manner through APIs so that it can be retrieved by external applications. The technician at ACME could use a field maintenance application that only needs to know the “description of the machines in production” (model, characteristics, etc.) and the application would then retrieve the relevant content from the different vendors through these remote APIs and dynamically create and display a purposely assembled document. Should the documentation evolve on the vendor side with updates, fixes, refined instructions, new images, or even the configuration of a machine, this would be automatically reflected the next time the technician opens their dynamically crafted document.
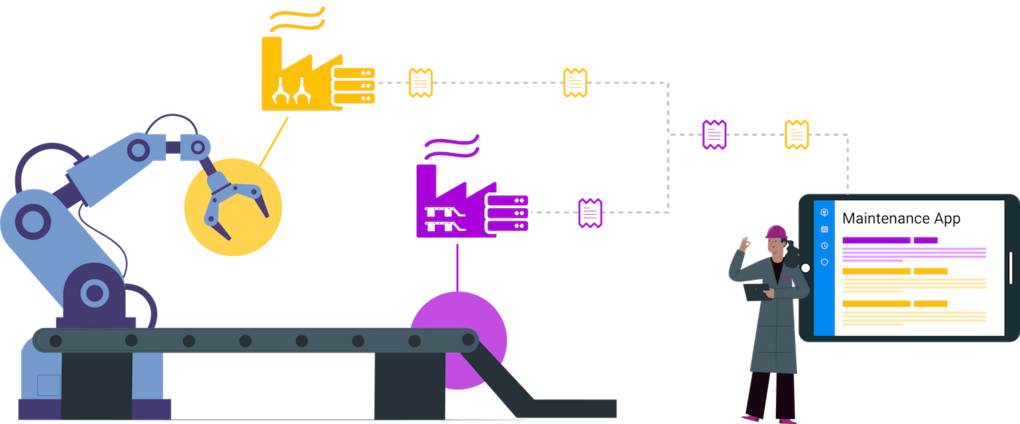
Figure 5: Tech Doc 3.0 – The Production Line documentation is dynamically assembled by retrieving the relevant content from different vendors
From a vendor perspective, it would be easier: The part of the documentation corresponding to the sub-systems embedded in the machine would not have to be written, but just referenced as it is generated by the provider. The vendor would just have to write the additional information that describes how to maintain that part in the context of its machine and otherwise point to the core documentation (drawings, images, instructions, and more) on the provider’s site.
A long shot or the next step?
Even if this vision of Tech Doc as an ecosystem of collaborating systems is likely a long shot, the emergence of formats such as iiRDS points to this direction by normalizing vocabularies and offering a way for machines to understand each other. Being business-driven and risk-averse, companies will continue to do as they have always done, and the progress towards Semantic Tech Doc will only come when the killer app has been found. It is likely that the IoT and Industry 4.0 along with the use case of preventive maintenance will be the trigger. With each machine being unique, the idea of generic documentation will become harder to support and the necessity of a documentation tailored to each machine will foster an evolution. Meanwhile, publishing platforms should get prepared and continue their maturation to support capabilities that expose their content to machines.
Conclusion
The Web has evolved from a network of static textual content to a social platform, and now to a way of exchanging knowledge at scale between servers. These evolutions should be carefully considered by the world of technical documentation, as they point in the direction of more efficient ways of working and engaging users. Tech Doc software solutions will be challenged to evolve and support these use cases, but perhaps the biggest challenge will be forcing the change of mindsets within companies that create Tech Doc.
Will you be among the first to move?