
Publishing documentation on the Web is more complex than it seems. To think that it is simply about generating HTML pages and uploading them onto a site is naïve and will almost certainly offer bad user experiences and lead to failure.
For decades, technical documentation was delivered in the form of printed books and binders, written by a small team, and shipped in boxes with the product. This approach has become obsolete. With the advent of computers, printed binders evolved into a dematerialized version of themselves: the PDF. These files were then copied onto USB keys or CDs, and shipped in boxes, transferring the cost of printing to the customer. The rise of the Internet in the 1990s provided the option to host these files on an FTP server so that users could download them on demand. As the Web matured, these same files were made accessible through websites.
However, it is not only the format that has changed but also the teams involved in generating documentation:
Printed manuals were passed from tech writers (as well as SMEs and reviewers) to printers, and then to logistics in a sequential process.
With PDFs, tech writers and IT (information technology) collaborate with overlapping activities and responsibilities. The tech writing team is often in charge of updating files in an infrastructure created and maintained by IT.
Albeit simple, this shift already contains all the seeds and indications of the transformation and complexity that is to come.
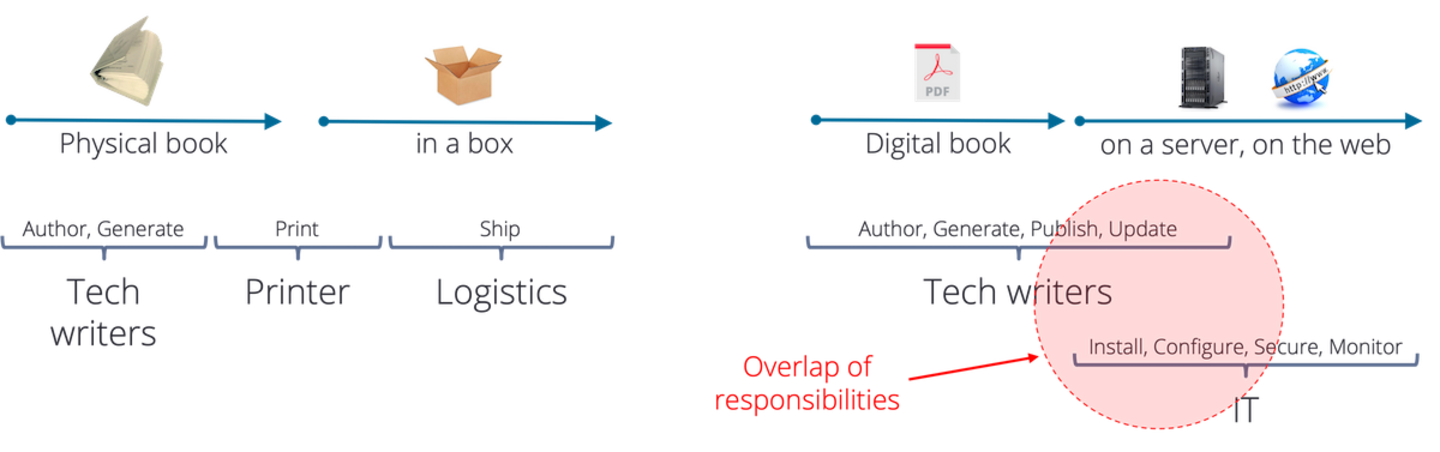
Figure 1: Doc publishing – form factor, delivery method, and the teams involved
Keeping in mind the main forces at play here – documentation format, delivery support, and teams – we can pass the intermediate documentation stage (including ebooks, CHM) and move to the present and the adoption of modern technologies: structured authoring, HTML formatting, and Web delivery.
Today, more and more people are aware of the value of technical documentation and how proper access to it has a significant impact on support efficiency and customer satisfaction. But it also involves more stakeholders – marketing, customer support, user experience, and more – providing input, influencing, or even deciding how documentation is presented on the Web. Yet few of these stakeholders understand the underlying complexity of publishing on the Web and offer inefficient solutions that often lead to project failure.
Delivering tech doc on the Web is complex, with a variety of pitfalls and challenges:
- Structure and granularity
- Organization and findability
- Stakeholders, design, and tools
Considering and overcoming these challenges with modern technology platforms open the door to a smoother, richer user experience, and a more efficient and profitable business outcome.
Structure and granularity challenges
Even when using a component-based authoring strategy, documentation is still primarily imagined as a series of stories organized in documents, reference guides, and manuals. The challenge here is a transition from a document rendered as a continuous flow of sentences and paragraphs to a set of discrete web pages.
When generating a PDF, there’s nothing to consider here: the granularity is the document, the components are assembled as one stream, and the pagination is enforced by the size of the paper. Yet when mapping the same documentation to HTML pages, there are many competing options. For example, you might create a single HTML page for each document, just as with a PDF. Alternatively, you might generate one page for each component or take an intermediate position such as one HTML page per chapter, section, or subsection.
Each approach has its pros and cons: A document rendered as a single HTML page is easier to navigate (simply scroll through it) but can be excruciatingly long to load in a browser. A page containing only one content component, on the other hand, loads rapidly but leads to tedious navigation – the next-prev button nightmare – and the users may lack context for the information they access. This can become a nuisance for users when small topics are designed to optimize the reuse of content.
This page granularity choice is key, as it has a significant impact on the end-user experience and on efficiency in finding and reading information.
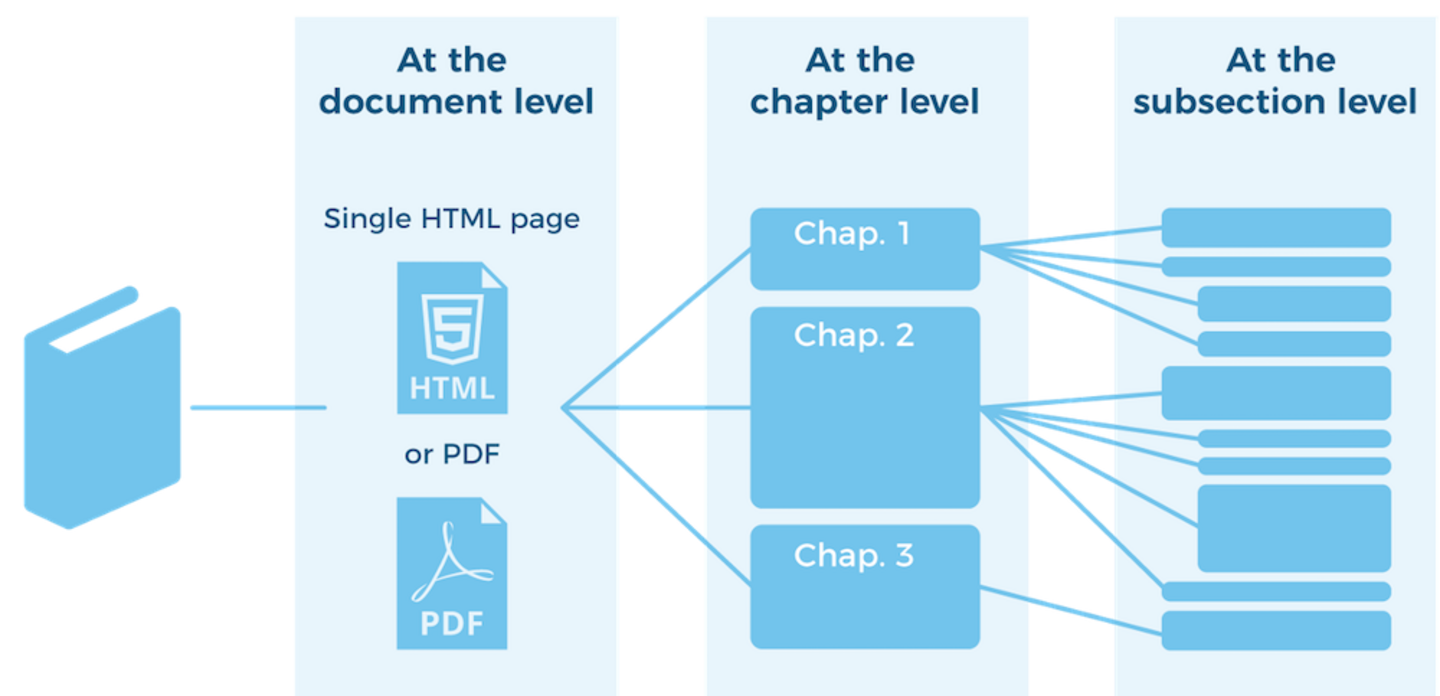
Figure 2: Generating HTML pages
In addition, consider the challenge of search relevance. Search engines index content at the chosen granularity. With a single HTML page per document, any search query will return all these long documents because they are keyword-heavy. These search results are likely irrelevant, and the user will be forced to search again through the entire document. Alternatively, if pages contain only one component and the user enters multiple keywords, no result may be returned as the searched keywords could be spread across different components and therefore different pages. A common solution is to choose an intermediate granularity to make the search relevant enough and provide a more positive user experience.
Yet, this creates other problems with regard to rating, feedback, or bookmarking features. The intermediate, coarse-grain level lacks precision and undermines the utility of these fine-grain options. It is much the same for precision analytics where the longer the page, the less you know exactly what users are reading.
Moreover, the page granularity may need to differ according to the type of content. For example, articles or troubleshooting tips might be rendered as one single page, while a reference guide could be effectively “chunked”. This granularity could even change dynamically according to the user preferences or the device used to access the content. What is served on a laptop or mobile device could be different from what is offered as online help or in AR glasses.
The point is that – while it is technically trivial to generate a set of HTML pages – there is nothing simple about rendering documentation as HTML. Modern content delivery technologies, however, can address the complexity of structure and granularity. They can dynamically assemble fragments of content as available in your authoring tool to create virtual HTML pages of a specific size according to set rules. Content Delivery Platforms (CDPs), like our own at Fluid Topics, don’t pre-generate any HTML pages. They maintain the granularity of content and build the page just at the moment of display. As a result, the actual HTML page size will vary depending on the type of content, the user, or the device, and clearly differentiate between a Web CMS and a CDP.
Content organization challenges
Technical documentation is not just any content. It reflects a company’s entire product line, which often includes different versions, a variety of customizations, and countless options, sometimes translated into multiple languages to serve global audiences. Hence, even the most generic of installation manuals will likely exist in a dozen different variants.
Structuring and organizing these different variants of the same content is a challenge on its own. Here, we need to choose between creating an intermediate page with all the variants of the document and creating a navigation tree with variants split across different pages.

or

Figure 3: Content organization dilemmas
And this is just for one manual. Every product in a range likely has several specific manuals and guides. Add multiple product lines across different product categories and the complexity only increases. This raises questions about the best way to organize the sets of HTML pages generated for each document, and for all variants of that document. Decision makers must therefore choose the optimal super-structure (that is, the intermediate navigation pages) to be built on. These structures are difficult to design and maintain as new products are added, old products removed, product lines reorganized, and new versions created or deprecated.
In the example shown in Figure 4, the user wants to access the information contained in the yellow component. On your homepage, she would have to click through multiple intermediate pages to find her product line, product, type, version, … enter the right document, and click until she finds the right page. A tedious, error-prone, and inefficient process.

Figure 4: Navigating complex hierarchies
As illustrated, such a complex hierarchy of pages can be incredibly difficult to navigate. Considering the complexity of managing these hierarchies, you might question why such navigation structures are used at all.
There are three primary explanations:
- It’s unconscious: It’s a website and, since the dawn of the Web, sites have been collections of linked pages often organized in a hierarchy.
- It’s historical: A company’s first documentation website that hosted vanilla PDFs had this navigation structure to link to the pages where each PDF was stored. When these PDFs were replaced by HTML pages, the umbrella navigation structure was retained.
- It’s forced: The tool selected to host and publish the HTML pages defaults to a tree structure.
Alternatively, a company can choose to be search-driven instead of navigation-driven.
|
|
Navigation-based: A lot of effort goes into organizing all content in a tree structure. Users must click through until they find the destination. | Search-driven: The main entry point to content for the user is submitting a query, possibly using filters to narrow down the search, and clicking on a result to reach the required information. |

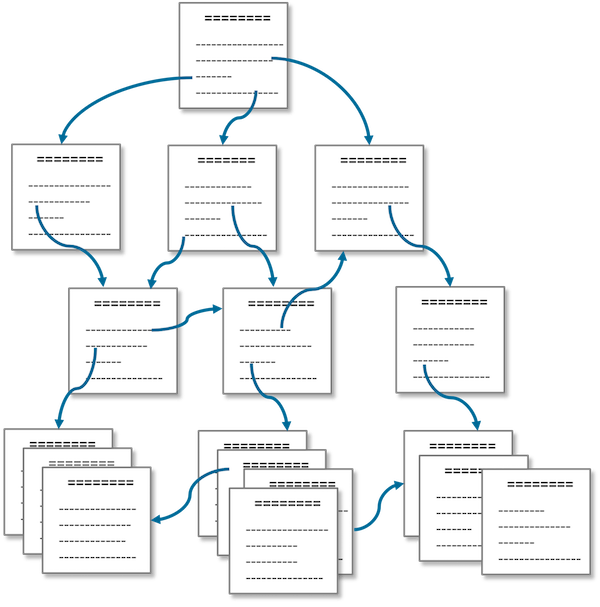

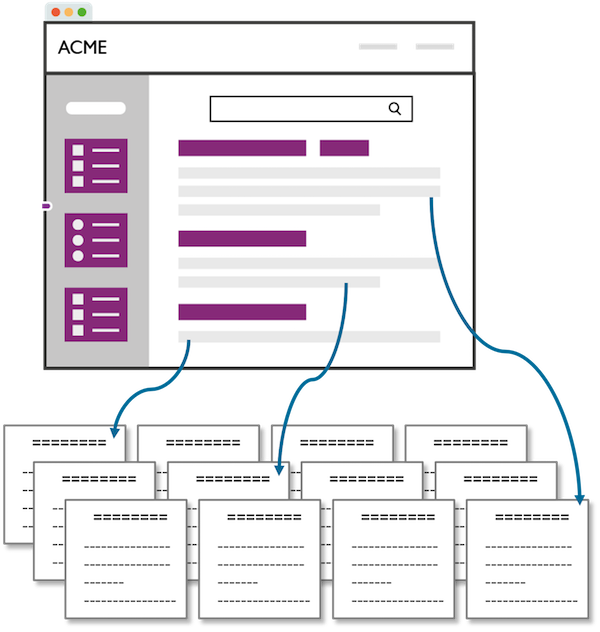
Figure 5: Content access alternatives
These two approaches have always been in opposition, but especially so in the context of the Web. When the first websites emerged in the early 1990s, users could locate and reach them by visiting directories such as Yahoo. They navigated pages that organized websites by subjects and sub-categories. In time, it became increasingly difficult to build and maintain these taxonomies, and users started to get lost in the wider Web. And along came Google. Categorizations and taxonomies were replaced by a single white page with a search box – and the web directory was dead.
In light of this history, it’s strange that companies continue to put effort into organizing content in hierarchies. Perhaps there is a lack of appropriate search technology that enables this transition. Yet, we should not leave navigation pages behind entirely. This becomes clear when considering the two distinct user motivations:
- “Show me what exists”: New users like browsing. They want to discover information, learn how it is organized, and map it to what they already know. Navigating through organized pages helps to grow their understanding.
- “I need this info”: Expert users prefer searching. They know the product and understand the scope of the documentation. They access the portal to solve a problem or to find an answer. They have no time for browsing the irrelevant and the fewer clicks they make, the better the experience.
When publishing content on the Web, it is important to address these two motivations and provide an appropriate solution for both. Building a navigation tree is not sufficient, and a top-notch search is a must-have. The good news is that a single effort can effectively address both simultaneously:
- Use the navigation tree as an implicit taxonomy. These intermediate pages and levels such as product lines, products, types, variants, versions, and languages are metadata values, and they can all be used to tag content. This turns your implicit sorting strategy into explicit content tags.
- Index the content and the metadata with a search engine that will leverage all these tags to provide filters to expert users (a.k.a faceted search) while delivering more specific capabilities such as dynamically grouping content variants (a.k.a clustering).
- Build navigation pages using the search engine. These pages can be dynamic and based on search queries; for example, a page that lists product lines and products can indeed be generated from search results. Pages don’t have to be maintained manually, invalid links are avoided, and security rights are maintained so that users will only see what they are allowed to see on these navigation pages. If the search engine is good enough, it will allow the rendering of navigation pages that are personalized to the user and that display results and content based on their individual profile and preferences.
Stakeholder, design, and tool challenges
Today, more people than ever understand the value of tech doc and want to be involved in – if not fully decide – how and where documentation is placed on the Web.
The where is the concern of stakeholders who are heavy consumers of tech doc and may want to have it available in their own work environment. Consider, for example, the customer support team. Its role is to reply to client questions and swiftly solve open cases to ensure optimal customer satisfaction. Its main tool is the service desk software, as this is the place where users find themselves when they have a problem they cannot resolve. As a result, it is common for a customer support team to claim that a dedicated tech doc portal is not how and where tech doc should be published, as it only creates another touchpoint; instead, that tech doc should be “in the helpdesk”. This is an understandable customer journey design choice, but a problem emerges from a strict interpretation of the phrase “in the helpdesk”.
Having tech doc available in the helpdesk to support case deflection and rapid case management does not mean that the content itself should be loaded inside the helpdesk tool. Being available in one place does not mean residing in that place, especially when the tool is not built for that. Helpdesk tools can create and manage knowledge base articles, which are HTML-based individual pieces of content that can be roughly tagged. This feature has been designed for support agents to create fast replies to recurring questions.
Yet, it cannot and should not be used to host tech doc – by force-loading pre-generated HTML pages of tech content as knowledge base articles. The complexity of granularity and the structure of technical documentation make it impossible to be effectively mapped to a flat list of disconnected articles. Any resulting user experience – whether searching or navigating – will be disastrous, and what was an effort to simplify a user’s life only makes it worse.
The target user experience can be attained, though, by having the tech doc hosted and served by a Content Delivery Platform (CDP) with a live connection, through APIs, between the helpdesk and the CDP. This multi-channel delivery layer with headless capabilities is exactly what a CDP is built for.
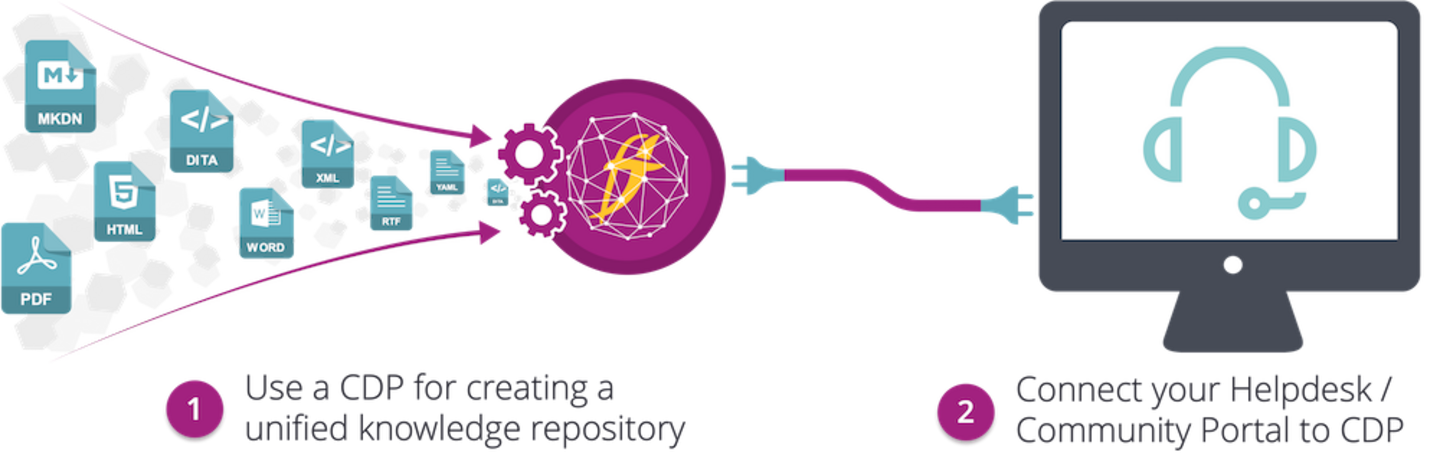
Figure 6: Connecting the display layer to the knowledge hub
Thus, if the customer support team reaches out and wants to take ownership of tech doc delivery, be prepared to resist, explain, and present the collaborative path to follow: The tech doc team should own the CDP and the customer support team should own the helpdesk.
Similarly, the marketing or UX/UI design teams might seek to take control of the tech doc. With tech doc live on the Web and gaining greater visibility to a world of users – and as it plays a role in brand awareness through SEM-SEO (Search Engine Marketing and Search Engine Optimization) efforts – marketing rightly feels they have a duty to apply their knowledge and practices to the tech doc.
A marketing team might propose – or even impose – the use of their existing tools for the delivery of content, most commonly a Web CMS used for the corporate website such as WordPress, AEM, Drupal, or Contentstack. For all the reasons previously mentioned – granularity, structure, and navigation vs. search – this is not ideal and will only result in a poor user experience. As the experts in tech content, you will be tasked with explaining why.
There will be additional demands on the design side, too: branding, page layout, navigation, and more. In responding to these design demands, it is important not to miss the forest for the trees. Aligning tech doc with corporate branding is one thing, but over-designing the user interface is quite another. Keep in mind that the star of the page should be the content and that the reading experience should be in the front of the mind. Keep the design simple, uncomplicated, and efficient. Do not clutter the interface; try to reduce the maze of navigation, put search and relevance front and center, consider a responsive UI, prioritize accessibility, and lean into personalization.
It's important to be sure that the CDP can support all these choices, including the tools to build a doc portal without heavy custom web development that only becomes a burden to maintain and an eventual legacy constraint. Low code is now a must-have and, with it, you can create a seamless journey by using the same single sign-on (SSO) and branding so that users don’t even notice when they switch from the corporate site to the doc portal.
Moreover, it’s important to remind marketing and design teams that tech doc is not just any other content. It is created for educating and supporting users in using and servicing products. Just as people used to interact with paper-based content by highlighting text, taking notes in the margins, and adding sticky notes to pages, tech doc content needs to offer similar functionalities. It is something that a Web CMS, a helpdesk tool, and custom software do not provide: These are key capabilities that users demand and that a dedicated, purpose-built CDP can deliver.
Finally, the IT team will almost certainly impose more requirements on tech doc. They’ll expect the capacity to connect the CDP to other tools in the corporate infrastructure, and the Infosec team will demand security assurances. No matter how powerful and feature-rich a tool might be, there is no way it will be adopted if it puts the business at risk of a cyber-attack. This, in turn, adds to the requirements and complexity of delivering tech doc on the Web.
Conclusion
We are living in exciting times, when technical documentation is emerging as a first-class citizen in many companies, creating an opportunity for radical transformation and operational efficiency.
But getting tech doc onto the Web is not simply about generating HTML pages and creating a website. It is significantly more complex, requires specific tools that reflect this complexity, and demands supporting and balancing all the requirements and perspectives of a new group of stakeholders. Tech doc teams need to be prepared to respond to this complexity, to respond to it with aplomb, and to prepare their stakeholders for the rewards that await efficient and effective execution.