
In our globalized world, the demand for translations is increasing at a staggering speed and can no longer be met by human translation alone. Yet, machine translation (MT) has long been criticized for its lack of translation quality. It is only recently that we have seen significant advances with the advent of Neural Machine Translation (NMT).
Previously, the main paradigms in machine translation were the rule-based and the statistical approach. In the rule-based approach, language experts tried to describe language in terms of linguistic rules. However, they failed to do so consistently and comprehensively because natural language is complex and ambiguous, and contains many irregularities. The statistical approach showed noticeable progress: Here, a machine “learns” how to translate by looking at large collections of human translations and trying to find statistical regularities between the sentences of the source language and their translations in the target language. For example, a simple regularity would be that if an English sentence contains the word “milk”, its correct German translation would usually contain “Milch”. Things get a bit more complicated with ambiguous words such as “palm”, whose two main meanings are related to “tree” or “hand”. To identify the correct translation, the context of “palm” can be statistically analyzed. If associatively related words such as “tree” or “coconut” are found in its context, it is likely that the correct German translation is “Palme”. If, on the other hand, words such as “finger” or “hand” co-occur, it can be expected that the correct translation is “Handfläche”. This will not work perfectly in all cases, but it improves the chances of a correct translation.
Although the statistical approach was a clear step up from the rule-based approach, one serious issue could not be resolved over decades: The n-gram language models used in statistical systems could only take into account short-distance dependencies between words, typically comprising just three words. Therefore, the meaning of “palm” would be correctly identified in the sentence “The palm tree is tall”, but not in the sentence “The palm on the other side is a tall tree” because in the latter case there are too many other words between “palm” and “tree”.
How artificial neural networks evolved
Neural systems have managed to resolve this issue because they can consider interdependencies between words over much longer distances than three words. In fact, taking long-distance dependencies into account is an inherent feature of neural networks. Another important breakthrough of the neural approach is that it is strong in considering different levels of language analysis simultaneously – such as morphology, syntax, and semantics – thus making it possible to take interdependencies across levels into account. This had been less successful with rule-based systems, as they tended to process language levels separately and primarily considered dependencies within levels.
As the name suggests, the technology underlying NMT is inspired by natural neural systems. Current systems only use the core concept, which is networks of neurons connected by synapses. Artificial neurons are far less complex than natural neurons, which is why artificial neurons are often simply referred to as nodes and the synapses as weights. Yet, artificial neural systems can be much faster than their natural counterparts, with modern semiconductor technology allowing switching times for the underlying hardware in the order of nanoseconds rather than in the milliseconds that we find in natural systems. This means that artificial neurons can be a million times faster.
Neuron = Node = accumulates activities Synapse = Weight = stores information |
How NMT works
First, let us get an overview of how artificial neural networks work in general, before moving on to how they are applied in machine translation.
By their nature, neural networks can be used for calculation. As an example, the neural network shown in Figure 1 is meant to compute dress sizes of persons from their body dimensions. The advantage of a neural network is that we don’t need to discover the (potentially highly sophisticated) mathematical formulas of how to do this. Instead, the neural network has to be trained using sample data. Imagine we have collected the body dimensions of 1,000 persons together with their dress sizes. We would now feed the body dimensions of the first person into the input layer of the neural network, and the same person’s dress sizes into the output layer of the network (which during training also serves as an input). Then a learning algorithm is applied to the neural network adjusting the weights (connections) between the nodes (neurons). We repeat this for the data of all 1,000 persons and, to deepen the training process, go over the entire training data several times until the network converges, i.e., until the weights do not change anymore with further repetitions.
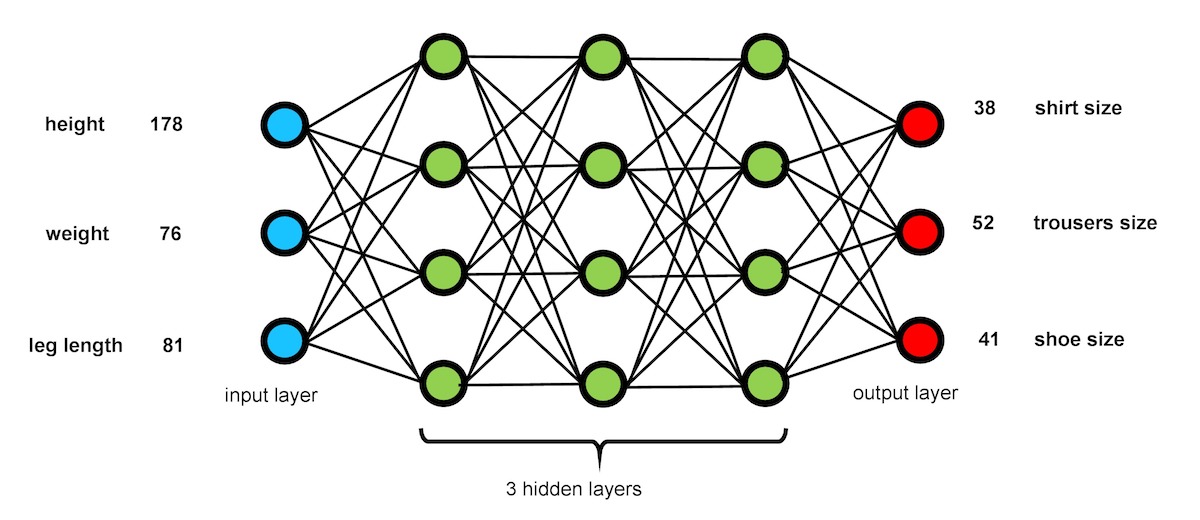
Figure 1: Sample neural network. It is simplified insofar as networks for real-world applications require thousands of neurons and more than three hidden layers. Each of the numbers at the input and output need to be represented by several neurons each.
Once the training has been completed, we can use the network for generation. In this mode, we just feed body dimensions into the input layer of the network, and the network will compute the dress sizes by itself. The magic of neural networks is that this will not only work when feeding in the body dimensions of the 1,000 persons the network was trained with, but also for new persons who will usually have somewhat different body dimensions. However, it is impossible to tell in advance how good the results will be, as a system with thousands or millions of weights has to be considered a black box, and the quality of the results can only be judged empirically by checking it with test data that was not used during training. Typically, a neural system will produce reasonable results only if the training data is representative of the input data to be fed in generation mode. In our example, it would be a mistake if we trained the system only with data from mid-sized persons, as this could produce poor results for children or basketball players.
The algorithm used in generation mode is fairly straightforward: The numbers on the input side are converted into activity patterns of the input layer – a standard task in neural computing for which a number of different approaches exist. Then these activities are propagated towards the output layer in such a way that larger weights transfer more activity, and smaller weights transfer less activity. The nodes simply sum up the activities they receive on their left (input) side and output the computed sum on their right side.
While the algorithm for generating results is comparatively simple and does not require a lot of computational power, this is not the case with the algorithm used for training the network. This learning algorithm solves the sophisticated problem of changing each of the weights in the network appropriately. A widely used algorithm for this purpose is the so-called backpropagation algorithm. Roughly speaking, it works as follows: Given the body dimensions of a single person, the neural network is first used in generation mode and the respective dress sizes are computed. However, as long as the training is not completed, the computed dress sizes are likely to be wrong. Therefore, the backpropagation algorithm takes the correct body sizes from the training data and computes the difference between the computed dress sizes and the correct dress sizes. These differences are called the error. The error is then propagated backwards through the network (i.e., from right to left, therefore the term backpropagation), and all weights are adjusted in such a way that the error on the output side is slightly reduced. It must not be reduced to zero in one go as the network is not supposed to directly memorize individual input/output data pairs, but instead should encode in its weights a pattern that averages over all input/output data pairs. To achieve this, the learning process has to be kept slow because it is the only way the network will be able to make good predictions for unseen input patterns in generation mode.
Neural networks for machine translation
In the case of machine translation, we deal with words rather than numbers. But this is not a major problem as words can easily be encoded into numbers. For example, if we wished to deal with a vocabulary of 100,000 words, we could simply sort the words alphabetically and assign each word the number corresponding to its position in the sorted list. Alternatively, we can do the same thing with syllables rather than words. This way we can reduce the size of our list, and the neural network will be able to better deal with new word creations (as long as they are made up of known syllables).
A much more severe problem than converting text into numbers is that texts can be very long. In NMT, a partial solution is that we limit ourselves to one sentence at a time, which is the current state of the art in machine translation, although there are now experiments with document-level MT. However, even neural processing on the sentence level is a challenge, as sentences can be rather long. To feed the words (or syllables) of a sentence into a neural network, we need several neurons per item. This requires large neural networks that can overstrain even modern computers. Fortunately, so-called recurrent neural networks offer a solution. These only look at partial sentences at a time, but take the previously processed parts of the sentence into account by a feedback loop that uses the output of the previous step as part of the input of the next step. As an alternative to recurrent neural networks, as is done in Google’s transformer architecture, a so-called attention mechanism can be used, which has a similar effect.
For NMT, two neural networks are used in sequence. This is called an encoder/decoder architecture, as illustrated in Figure 2. Note that we have recurrent networks here, which is indicated by the arrow pointing back from the third to the first hidden layer. The network on the left side is called an encoder. It generates a vector from the source language sentence that is supposed to carry the meaning of this sentence. This vector, which is sometimes referred to as a sentence embedding, is then transferred into the target language using the second neural network called a decoder. The reason why we need this kind of dual system is that the networks are recurrent with a feedback loop. Both the encoder and the decoder require this feedback loop. The two networks cannot be merged into one, as these loops are only possible within a language, but not across languages.
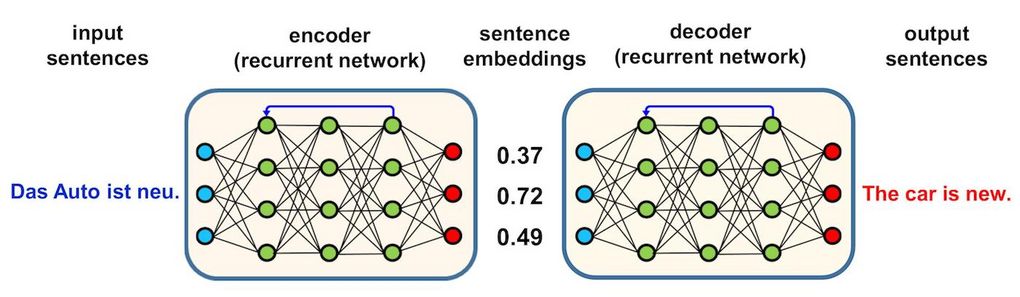
Figure 2: Encoder/decoder architecture for NMT.
Building your own NMT system
Building an NMT system from scratch would take years, as it would involve the programming of sophisticated algorithms (such as backpropagation) and several helper tools needed for text processing. Fortunately, this is not necessary, as there are readily available open-source toolkits that we can use as building blocks for our own system. This saves time and allows us to focus on the parts we are most interested in.
The NMT toolkit we suggest here is Marian NMT (Junczys-Dowmunt et al., 2018), although there are alternatives such as OpenNMT and FAIRSEQ. Marian NMT is a well-established high-performance system that works so well that Microsoft hired its main developer (Marcin Junczys-Dowmunt) and adopted it as the basis for its Microsoft Translator. Marian NMT supports the latest transformer models (Vaswani et al., 2017) as well as previous models using recurrent neural networks. It is also very fast, as it is written in the low-level programming language C++, and supports multi-GPU and multi-CPU training. Traditionally, it runs under Linux, which is open source and dominates the MT server market, but recently a version for Windows has also been released. However, as this is still new, we currently recommend it only for advanced users.
Setting up your own NMT system using Linux involves the nine steps described below. The scripts mentioned can be downloaded from our webpage at sites.google.com/view/mttutorial, which also provides further instructions. The scripts are modified versions of scripts found in the Marian NMT documentation.
Step 1: Check if your hardware is suitable
A standard Windows PC or laptop can be used. Minimum requirements are: 16 GB of RAM, reasonably fast CPU (e.g., Intel i5, i7, i9; AMD CPUs are also possible), 200 GB hard disk (conventional or SSD), Nvidia GPU with at least 8 GB of graphics memory (i.e., on the GPU). GPUs from other manufacturers are not supported (e.g., AMD). If you do not have an appropriate GPU in your computer, you can do without it, but you must be prepared for the system requiring several weeks for training. Fortunately, training is a one-time process per language pair (unless you wish to experiment with different parameters). If the system crashes during training (e.g., due to power failure), Marian NMT will recover, as it stores the training status in regular intervals.
Step 2: Install Ubuntu
Assuming you have a Windows PC, you need to install a Linux operating system. We recommend Ubuntu 20.04 (LTS, i.e., providing long-term support) that has been tested extensively with Marian NMT. Installation instructions are given at ubuntu.com/download/desktop. In principle, it is possible to test Ubuntu without changing anything on your hard disk by installing it on a USB stick. But, as we need a high-performance system, this does not work here. However, you can install Ubuntu in addition to Windows. This way you will have a dual boot system: When starting the PC after installing Ubuntu, a boot manager shows up asking which OS you wish to use.
During installation, Ubuntu asks how much hard disk space you wish to allocate for the system folder and swap space. We recommend at least 50 GB for the system folder, and for the swap space at least half of your RAM size. A standard installation (rather than a minimal installation) helps to avoid having to install standard Linux tools manually later on. Note that the Windows NTFS file system can be accessed from Ubuntu, but Windows cannot access the Ubuntu file system.
Step 3: Install CUDA
CUDA (Compute Unified Device Architecture) is Nvidia’s software allowing you to use their GPUs for purposes other than the screen graphics they were originally designed for. These other purposes include running neural network software such as Marian NMT. If you don’t have an Nvidia GPU, you cannot install CUDA. In this case, Marian NMT will still run, but, as described above, the training will be very slow. Instructions on how to install CUDA can be found on Nvidia’s website at developer.nvidia.com/cuda-downloads.
Step 4: Install Marian NMT
To install Marian NMT, its source code must be downloaded from the internet and then compiled, i.e., executable code has to be generated from the source code. A few Linux commands are necessary to do this. For your convenience, we provide these in a so-called shell script so that you only have to start the script.
Step 5: Install tools for pre-processing and evaluation
To pre-process the corpus of human translations to be used for NMT training, we need several tools that can be downloaded from the Marian NMT website. These are the tools that you will need:
- Tokenizer: Splits sentences into words.
- Cleaning tool: Discards sentence pairs where either the sentence of the source or the target language is empty, or where both sentences have very different lengths. Such cases are often cause by noise in the data.
- True-casing: Sentence-initial uppercase characters are lowercased if the respective word is more common in the lowercase version. For example, “He walks” is replace by “he walks”.
- Subword segmentation: Words are split into high-frequency substrings. For example, “nonsensical” might be split into “non”, “sens”, and “ical”. As explained above, this helps NMT systems to deal with rare words not occurring in the training data.
- BLEU evaluation (Papineni et al., 2002): This is a tool that, by computing string similarities, compares the machine translation of a sentence to its human translation, which is assumed to be perfect. This produces values between 0 and 1, with 0 indicating a very bad machine translation that has no similarity to the human translation, and 1 indicating a perfect machine translation, which is identical to the human translation. Figure 3 gives an idea of how these BLEU scores are computed.
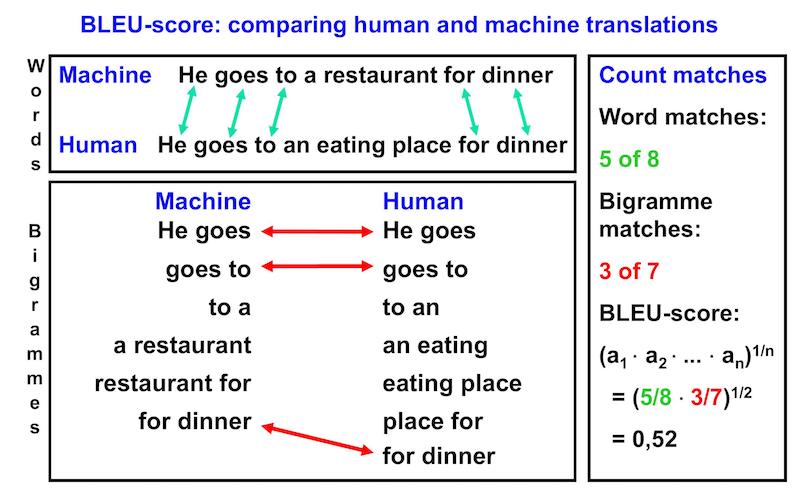
Figure 3: Basic concepts of computing BLEU scores (simplified). In practice, word sequences longer than bigrammes are also taken into account.
Step 6: Download and split the parallel corpus
For our first system, we suggest using the German/English portion of the Europarl corpus (Koehn, 2005). This corpus consists of translations of speeches held in the European Parliament and covers more than 20 official EU languages. We provide a script that downloads the corpus and splits it into a large part used for training and two small parts for development and testing. The development set is used for controlling progress during training, and the test set is used for evaluating the translation quality of the trained system. If we want to further improve our system later, we can add additional parallel corpora from other sources. We can either search the internet for “parallel corpus” and the names of the languages we are interested in, or we can go to the OPUS website at opus.nlpl.eu (Tiedemann, 2012). This is the largest website of its kind and provides huge amounts of parallel corpora in many languages, readily prepared for MT processing.
Step 7: Apply pre-processing on the parallel corpus
For this step, a script is provided that applies the pre-processing tools installed in step 5 to the training, development, and test sets obtained in step 6.
Step 8: NMT training
After pre-processing, the corpora are ready to be used for training. Training is conducted by a script that starts Marian NMT in training mode and provides settings for all required parameters. These include, for example, parameters that tell Marian NMT which architecture to use (in our case the transformer), or how many GPUs are available for training.
Step 9: Translation and evaluation
Once training is completed, the Marian decoder is started by using the respective script. This means that Marian NMT is now used in the mode for translating sentences. Here, the sentences of the test set are translated, and the results are automatically evaluated using the BLEU evaluation tool. Alternatively, any other source language text can also be translated. In this case, an automatic evaluation usually will not be possible, as this would require a human translation for comparison. Usually, this is not a major problem, because we already know the quality of the translations from the test set and can assume that similar types of texts will typically be translated with similar quality.
Translation results
Table 1 lists translations of a few sentences that were randomly selected from the test set. It can be seen that the translations are fairly good, though not perfect. The automatic evaluation gave a BLEU score of 38.0 for German-English. When compared to commercial systems such as Google Translate, they likely do even better. However, this comparison is not quite fair, as our system was trained with a tiny corpus in comparison to what the big players are using. If we want to improve further, we can train our system with much larger corpora that can be downloaded, e.g., from the previously mentioned OPUS website. However, to get off to a good start, it seemed more appropriate to use a smaller corpus requiring less training time.
German original sentences | Machine translation |
Es ist noch zu früh, die Folgen dieser Krise für die Realwirtschaft zu quantifizieren. | It is still too early to quantify the impact of this crisis on the real economy. |
Der von der Regierungskoalition gewählte Name ist sicherlich kein Zufall. | The name chosen by the coalition government is certainly not a coincidence. |
In einem Rechtsstaat - und das sind wir doch wohl - kann es vor dem Gesetz keine Ausnahmen geben. | In a state governed by the rule of law - and we are surely - there can be no exceptions before the law. |
Die Besteuerung von Personenkraftwagen lässt sich nicht von der allgemeinen Steuerregelung trennen, zu der die Mehrwertsteuer, die Einkommensteuer, die Verbrauchssteuern gehören, die im Übrigen ein Instrument für Haushaltseinnahmen darstellt und als solches der Souveränität der Staaten unterliegen muss. | The taxation of passenger cars cannot be separated from the general tax regime, which includes VAT, income tax and excise duties, which are, moreover, an instrument of budgetary sovereignty and, as such, must be subject to the sovereignty of the Member States. |
Table 1: Sample translations
Using the same scripts and changing only the language identifiers, we also tested our system with Spanish→English, French→English, and Greek→English and obtained BLEU scores of 43.6, 39.8 and 44.3, respectively. The ranking of our system in the 2021 edition of the Similar Language Translationtask at the 6th Conference on Machine Translation (Rapp, 2021), confirmed that it is indeed competitive (see Table 2). Here, the organizers provided training corpora larger than Europarl, and all teams had to limit their training to these corpora. The language pairs shown in Table 1 were not part of the competition, but within a week it was possible to adapt our system to Spanish-Portuguese and Spanish-Catalan, each in both directions. According to Table 2, whose scores were calculated by the organizers of the competition, our system achieved rather high BLEU scores, winning the competition for the language pair es→ca, and ranking second for the three other language pairs. The observation that ca→es and es→ca perform at extremely high BLEU scores between 78 and 80 can be explained by the fact that Catalan is very similar to Spanish, with differences mainly on the vocabulary side, but with almost identical syntax and semantics.
Language pair | BLEU score | Rank in competition |
ca→es | 78.65 | 2 |
es→ca | 79.69 | 1 |
pt→es | 46.51 | 2 |
es→pt | 40.35 | 2 |
Table 2: Evaluation scores of our system in the Similar Language Translation task
Conclusions
With current state-of-the-art NMT toolkits, it is possible for any company with translation needs to build its own high-quality NMT system. This system can be adapted to personal needs (e.g., specific domain) and new language pairs can be developed quickly as the underlying technology is largely language-independent. It is not even necessary for the developers to be proficient in the languages. However, post-editing is still indispensable for serious applications such as publishing documents.
It should be noted that it is almost impossible to beat the best commercial translation systems such as Google Translate, Microsoft Bing Translator, or DeepL, in the field they were designed for – namely the translation of general language. The reason is that these companies have invested considerable efforts not only in the underlying technology but also in searching the web for human translations and therefore have huge amounts of training data at their disposal for popular language pairs. But this is not the case for a plethora of lesser-used language pairs, many of which are not even covered by the big players. For such language pairs, you might have no other choice than to develop your own system. This also applies to companies or institutions that use a specialized corporate language, particularly if they already have training corpora at hand or can collect them. It is generally acknowledged that MT systems trained on special language can translate this specific type of language much better than universal MT systems. As the big players are not providing this, it has created a market for MT companies assisting MT users to develop their own specialized MT systems. If confidential documents are to be translated, privacy concerns are another important motivation for requiring in-house MT systems.
Acknowledgment
This work was supported by the Semantics-Based Machine Translation project (SEBAMAT; grant agreement number 844951) within the European Commission’s Horizon 2020 Framework Programme.
References
- Junczys-Dowmunt, Marcin; Grundkiewicz, Roman; Dwojak, Tomasz; Hoang, Hieu; Heafield, Kenneth; Neckermann, Tom; Seide, Frank; Germann, Ulrich; Aji, Alham; Bogoychev, Nikolay; Martins, André; Birch, Alexandra (2018). “Marian: fast neural machine translation in C++.” Proceedings of ACL 2018, System Demonstrations, 116–121.
- Koehn, Philipp (2005). “Europarl: a parallel corpus for statistical machine translation.” Proceedings of the Tenth Machine Translation Summit, Phuket, Thailand, 79–86.
- Papineni, Kishore; Roukos, Salim; Ward, Todd; Zhu, Wei-Jing (2002). “BLEU: a method for automatic evaluation of machine translation.” Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, 311–318.
- Rapp, Reinhard (2021). “Similar language translation for Catalan, Portuguese and Spanish using Marian NMT.” Proceedings of the 6th Conference on Machine Translation.
- Tiedemann, Jörg (2012). “Parallel data, tools and interfaces in OPUS.” Proceedings of the 8th Language Resources and Evaluation Conference (LREC), Istanbul, 2214–2218.
- Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Usz-koreit, Jacob; Jones, Llion; Gomze, Aidan N. G.; Kaiser, Lukasz; Polosukhin, Illia (2017). “Attention is all you need.” Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 6000–6010.