
In all our discourse about content – how to create it, manage it, reuse it, massage it, value it, govern it, and so on – how often do we consider its basic purpose? In my view, content has only two purposes:
Learning
Building relationships
In technical communication, we are most often concerned with learning, while our colleagues in marketing focus more on building relationships, though we all need to be concerned with both. Indeed, I would argue that, if we do a good job facilitating our users’ learning processes, then we are also helping to build a relationship between them, our products, and our companies.
The COVID-19 pandemic has changed the learning landscape dramatically, and probably permanently. Teleworking and eLearning are now planet-wide obligations. Our daily processes at home and in our professional lives have been reshaped by this reality, and pundits say this might not be the only such situation we’ll have to face in coming years. This “new normal” comes with an increasing dependency on communication technologies and on the connected objects of the Internet of Things driven by some sort of Artificial Intelligence (AI) which is fed by machine learning of one sort or another.
As researcher Ilkka Tuomi points out, when we talk about AI, we must be aware that we are not dealing with one technology, but with a series of layered sub-disciplines, each with its own history, domains of expertise, and developmental dynamics. [1] The parts of AI concerned with learning, with some examples of each technology, are shown in Table 1.
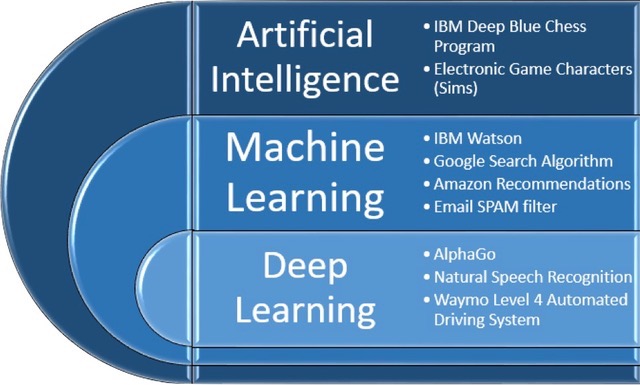
Table 1: Learning domains of Artificial Intelligence
Source: Ray Gallon, after Ilkka Tuomi
Some additional applications that come out of these technologies include:
- Speech recognition
- Virtual agents such as “chatbots”
- Decision management
- Biometrics
- Textual analysis
- Modeling and “digital twinning”
- Content creation
- Emotion recognition
- Image and sound recognition
By the time this article is published, this list will probably be much longer – such is the pace of AI development today.
AI and human learning
As machine learning advances and changes, so does human learning. Traditionally important epistemic components of learning, such as domain knowledge, experience, tools mastery, or acquired skills, are taking a back seat to “soft skills” such as:
- Creative problem-solving
- Learning to learn
- Meta-cognitive capabilities:
- Self-reflection
- Emotional intelligence
- Capacity to mobilize social resources and knowledge
Above all, the prime skill today is connectivism. In today’s hyperconnected, AI-driven world, where more and more machines are making autonomous decisions without human intervention, what you know is less important than how you mobilize your knowledge. Social, cultural, and communicative abilities are more important than epistemic learning; critical thinking and design thinking are more important than skills acquisition – or rather, they have become the skills we need to acquire so that we can continue to learn throughout our lives and our careers. Traditional user manuals and online help systems are rooted in epistemic learning. Can we develop new learning paradigms for technological products that are in step with the educational evolution?
AI is clearly an important motivating force that is changing our learning paradigms. It can also offer a variety of tools to facilitate these new modalities. In their 2019 book, Artificial Intelligence in Education: Promises and Implications for Teaching & Learning [2], Wayne Holmes, Maya Bialik, and Charles Fadel identify two classes of learner-facing applications:
- Applications that teach:
- Intelligent tutoring systems (including automatic question generators)
- Dialogue-based tutoring systems (similar to chatbots)
- Language learning applications (including pronunciation detection)
- Applications that provide support:
- Exploratory learning environments
- Formative writing evaluation
- Learning network orchestrators
- Language learning applications
- AI collaborative learning
- AI continuous assessment
- AI learning companions
- Course recommendation
- Self-reflection support:
- Learning analytics
- Meta-cognitive dashboards
- Chatbot training as a learning experience
Clearly, the support domain is where most of the interest lies, and one of the chief aspects of support is providing highly personalized, contextualized learning. This means conditioning the material to learners’ strengths or weaknesses, modulating the way it is presented based on their emotional responses, detecting what tasks they need to accomplish and providing appropriate help, etc.
While the grail of deeply personalized learning may appear imminent, there is less evidence about how effective it may be. Ilkka Tuomi, in a report to the European Parliament, declares that
There is relatively scarce evidence about the benefits of AI-based systems in education… learning outcomes do not depend on technology. It depends on how the teachers can use technology in pedagogically meaningful ways. An appropriate approach, therefore, is to co-design the uses of technology with teachers.
In other words, as we already know in many other domains, we will not improve learning (including of technical content) by throwing technology at it. The real solution lies in a blended collaboration of human and machine learning and intelligence.
In a technical communication context, then, where do teaching and learning take place? How can we evaluate the effectiveness of the solutions we employ? How can we adequately measure how our users experience the learning process in hybrid human-machine systems?
Qualia – the experience of experience
AI is still far from achieving the complex qualitative perception that humans experience when communicating with and learning from each other.
Machine learning focuses on data. Processing big data is critical to its algorithms that recognize images, texts, sounds or objects, and interact with humans. While human-to-human communication is simultaneously multisensorial and plurifactorial (even endorphins have their role), human-machine interaction is still limited to a reduced number of channels at a time, and at most bi-sensorial (audio-visual).
The characteristics of these complex human subjective experiences are known in philosophy as qualia (singular quale), and they are viewed as unique and untransferable. Philosophers relate them to feeling, resistance, mediation, or intuition. The philosopher Daniel Dennett identified four properties that are commonly ascribed to qualia:
- Ineffable: they cannot be communicated or apprehended by any means other than direct experience.
- Intrinsic: they are immutable and do not change based on the experience's relation to other things.
- Private: therefore, all interpersonal comparisons of qualia are systematically impossible.
- Directly or immediately apprehensible in consciousness to experience a quale is to know one experiences it, and to know all there is to know about that quale.
They are considered too diffuse and intangible to add scientific value to studies on human cognition. As an example, when you drink a particular cup of coffee at a given moment, you have a singular experience that is your perception of what it is like to drink that particular cup of coffee in that particular moment. Such an isolated experience is a quale, unique to you, to the moment, and the particular cup of coffee you are tasting. This makes it clear that the experience of a quale is totally subjective, a response to the question “what is it like” to have an experience or to be somewhere, do something, etc. As such, it is untransferable and should be considered an inappropriate theme for scientific investigation. By its very nature, this understanding of qualia is also a concept about which Artificial Intelligence can know nothing.
On the other hand, as a modern philosophical concept, qualia can refer not only to personal perception, but also to its individual interpretation, and includes personal awareness of both. Under this extended definition, qualia can be commonly represented using explicit communication (messages), fixed language and, in part, by certain external relations between individuals and their environments, also shared through language. Continuing with the previous example, the taste of a cup of coffee is a general, subjective experience that many people can share collectively with texts, images, sounds, etc. as common codes that help understanding and that represent a special social atmosphere or a shared cultural context.
In User Experience (UX), we are also dealing with subjective impressions that can be difficult to define or communicate. Every user’s experience with a product is unique, personal, subjective, and intangible – a quale, or a set of qualia. To help us evaluate user experience, we content specialists can borrow from the realm of philosophy and build UX descriptions based on different qualia. When these experiences are shared – i.e., made visible – they suddenly become relevant as objects for study. We can use them to build models such as ontologies, classified according to specific instances of subjective perceptions, personal interactions (with the product and with other users of the product), and social models that grow out of these interactions.
How to measure qualia?
Industries are driven by metrics, and although intangibles are gaining importance in parallel with soft skills, we still need to justify the approaches we use in some quantitative manner. If we stay with the coffee-drinking example, we could study measurable aspects of human behavior and social attitudes when drinking a cup of coffee, and find correlations, similarities, and differences about the act (data on coffee consumption, mapping, cost, and price per kilo), communication trends about the act (e.g., industry publications, publication frequency, trends in coffee advertising and marketing materials), or even the impact and consequences of the communication process itself (e.g., impact on the stock market from a study of coffee and health, product image based on feelings or opinions about such information, etc.). All these collective responses generate a visible flow of quanta – the Latin word for amounts (singular quantum), usually used today to refer to the smallest possible discrete unit of any physical or virtual element. Such quanta, when correlated and aggregated, form a usable pool of measurable big data about subjective experiences. These data are accessible to AI, and the hopes for delivering highly-contextual, personalized information in real time stem from the analysis of it.
Data-driven AI, still the most common type of machine learning algorithm, is a very sophisticated form of statistical analysis. Combined with personal profiles of each user and data from the user’s context in real time, AI can make correlations about what kinds of information to deliver in that user’s current situation, and even in what voice and tone that information should be delivered. In other words, contextual machine-to-machine information provides enormous possibilities for personalized machine-human information delivery.
Ultimately, however, the driving energy for this transformation does not come from technology, but from the manner in which people experience and react to technology. Analyzing these layers of people’s explicit information is not easy for obvious reasons (language, subjectivity, arbitrariness, sincerity, etc.), and this fact has marginalized qualia compared to objective data that is commonly collected automatically. But there are strong reasons to start integrating qualia as valid information to better understand the UX and the users’ learning processes.
While explicit information can be communicated by people (e.g., I drink a cup of coffee every morning, and one in the afternoon but never after five o’clock), AI is able to detect, recognize and learn directly from the event plus the environmental correlation (e.g., how many cups of coffee are paid with a card in a particular time, place or currency).
At the same time, care must be taken to manage the sort of cognitive bias that enters regularly into machine learning algorithms when the training database has not been vetted by humans (e.g., in the previous example, gender and location can take on different significance in different cultures. In some places, men are expected to pay for a woman’s consumption, women can’t consume coffee in public places, and tea is a culturally oriented alternative at a particular hour). Human intervention is essential to correct data processing and help the algorithm adjust for qualia that are invisible to machine learning processes. This has already raised, and will continue to raise, a plethora of ethical questions that are far from being resolved.
Consequently, the only way of enriching the whole picture is by combining human and machine information. We know that emotion plays a critical role in learning success, and if we want to build engagement with our users, and ultimately adhesion and loyalty to our products, we need to act on both quanta and qualia, and be able to evaluate and report our results.
Fortunately, there are tools we can borrow from the world of education and adapt to our needs. One example is the Short Grit Scale Test, developed in 2007 by A. L. Duckworth, C. Peterson, M. D. Matthews, and D. R. Kelly, shown in Table 2. This scale of eight items can be used to assess a learner’s level of “grit”– sustainable motivation based on personal passion and the perseverance to achieve goals. This example has been slightly modified by the author and Neus Lorenzo to be more specific to learning in technological, and especially AI environments.
Characteristics | Scoring | |
1. New ideas and projects sometimes distract me from previous ones. |
|
|
2. Setbacks don’t discourage me. |
|
|
3. I have been obsessed with a certain idea or project for a short time but later lost interest |
|
|
4. I am a hard worker. |
|
|
5. I often set a goal but later choose to pursue a different one |
|
|
6. I have difficulty maintaining my focus on projects that take more than a few months to complete |
|
|
7. I finish whatever I begin |
|
|
8. I am diligent |
|
|
Add up all the points and divide by 8. |
| |
Table 2: The Short Grit Scale Test
Evaluating user experience – not just “likes”
Social media scoring methods (views, likes, responses, retweets, star ratings, etc.) are just the tip of the iceberg of indicators that can be tracked and collected with context sensing in smart devices during digital interactions. Platforms can track not only raw quantities such as how many “likes” a post receives, but the flow across the network as users influence each other through their scoring of different posts. These platforms are profiting from metadata-rich information. For AI learning systems, we need new specialized metadata taxonomies to help track information in ways that can be extremely relevant when processed for learning purposes, but also extremely worrisome if used without ethical concerns or respect for privacy.
Explicit quantitative information on what a user does when learning a task needs to be complemented with information about the factors that condition their knowledge-building process and examined against general trends of common behavior (social expectations). As we explore how people react, we are effectively adding a new set of qualia related to digital ethics and the common good.
To evaluate all this, we need to be able to track the strategies learners use, and how they apply them when learning with AI technology. An existing taxonomy, the Big Five, or OCEAN model, has been evolving for decades. The author and Neus Lorenzo adapted Lewis Goldberg’s work on this model to create an evaluative scale for AI learning. See Table 3.
AI learning indicators, adapted from Goldberg’s Big Five structure
| ||
AI learning need | Indicator | Descriptors |
Plasticity in AI learning interaction | Extraversion: - Enthusiasm | The learner’s ability to be sociable, talkative, and comfortable in social situations. |
Openness: - Intellect | The learner’s positive attitude towards curiosity, intellect, creativity, and innovative ideas. | |
Stability in AI learning interaction (the learner’s stability when learning in an AI environment, capacity to maintain shape, state, quality, or degree in spite of external stress) | Agreeableness: - Compassion | The learner’s sensitivity and affability, tolerance, trust, kindliness, and warmth. |
Conscientiousness: - Industriousness | The learner’s organization, systematization, punctuality, diligence, orientation to achievement. | |
Neuroticism: - Withdrawal | The learner’s irritability, anxiety, and moody temperament in certain circumstances. | |
Table 3: Big Five Scale for AI Learning
While there is no one-size-fits-all magic solution, the study of qualia in user experience can help us understand how humans and machines need to interact in the 21st century. Adding qualia into the mix provides us with tools for evaluating and enhancing user experience in AI learning environments.
References and further reading
[1]Research for CULT Committee - The use of Artificial Intelligence (AI) in educationby Ilkka Tuomi, Report to the European Parliament, May 2020.
[2]Artificial Intelligence in Education: Promises and Implications for Teaching and Learningby Charles Fadel, Wayne Holmes, and Maya Bialik, independently published on Amazon, 2019.
[3]Learning to Learn with Machinesby Ray Gallon, tcworld magazine, October 2019
[4]Context Sensing and Information 4.0 by Ray Gallon and Andy McDonald, tcworld magazine, November 2016